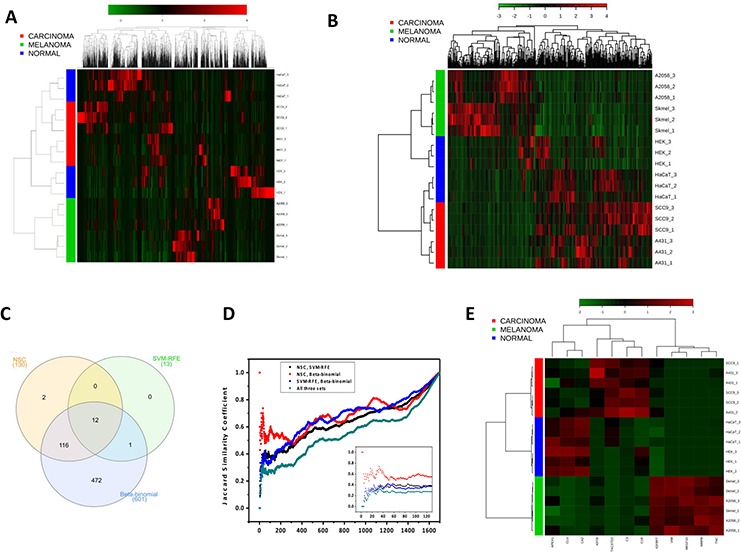
In this project I implemented a pipeline in R to rank and select proteins based on three different Machine Learning ranking approaches: multivariate, univariate and semi-multivariate. The methods were SVM-RFE, Beta-Binomial and NSC. The project was developed in colaboration with the Brazilian Biosciences National Laboratory and experts from different fields.
The dataset was a result from a Discovery Proteomics quantification, which resulted in a high number of variables and low number of samples. For this reason, we implemented the multivariate and semi-multivariate classifiers/rankers in a Double Cross Validation scheme.
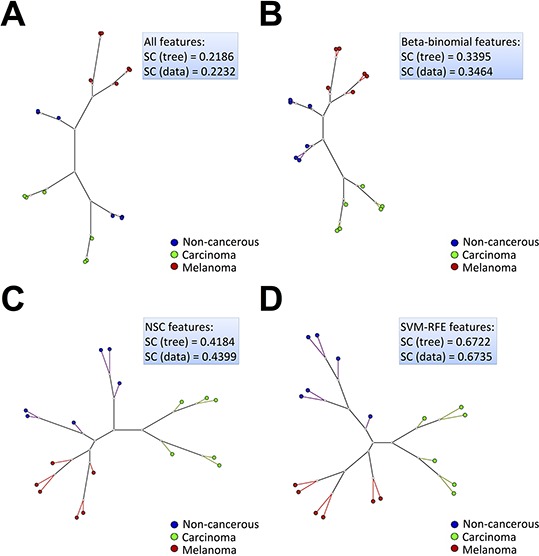
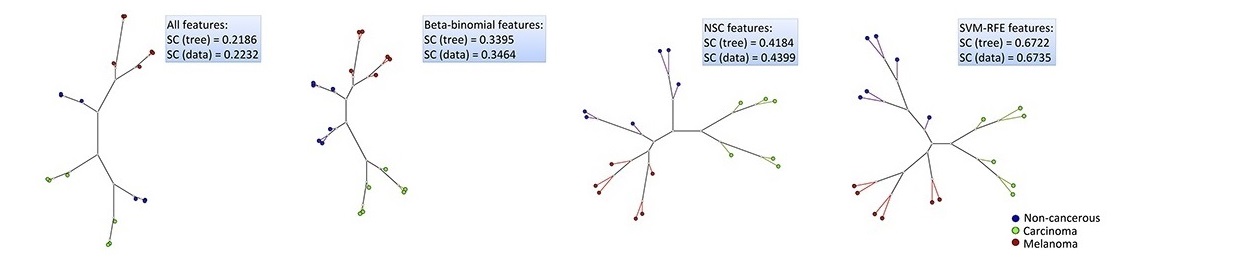
Multidimensional projection and trees visualization helped us to understand the data and the results.